
Forwarded from AI Pulse (Mohammad)
شرکت متا نسل چهارم از مدلهای زبانی Llama را معرفی کرده که با تواناییهای چندوجهی و پشتیبانی از کانتکست بسیار بلند، رقیب بسیار جدیای برای مدلهای اوپن سورس محسوب میشن.
در این مجموعه سه مدل معرفی شده: Llama 4 Scout، Llama 4 Maverick و Llama 4 Behemoth. دو مدل اول به صورت Open Weight عرضه شدن و برای استفاده در پلتفرمهایی مثل WhatsApp، Messenger، Instagram Direct و نسخه وب Meta AI در دسترس قرار گرفتن.
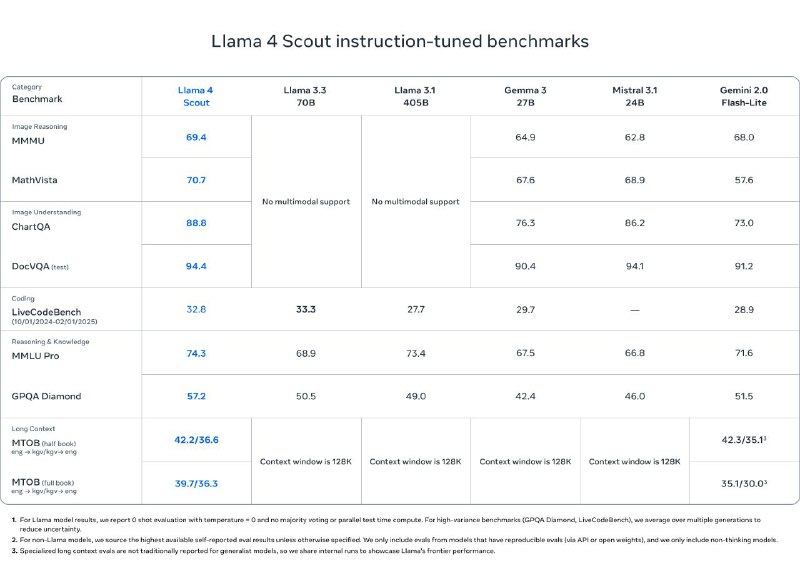
مدل Scout با ۱۷ میلیارد پارامتر فعال و ۱۶ متخصص، قویترین مدل توی کلاس خودش بهشمار میاد و با وجود تواناییهای چشمگیر، روی یک GPU از نوع H100 اجرا میشه. این مدل با داشتن پنجره کانتکست ۱۰ میلیون توکنی، عملکردی بهتر از مدلهایی مثل Gemma 3 و Gemini 2.0 Flash-Lite ارائه میده.
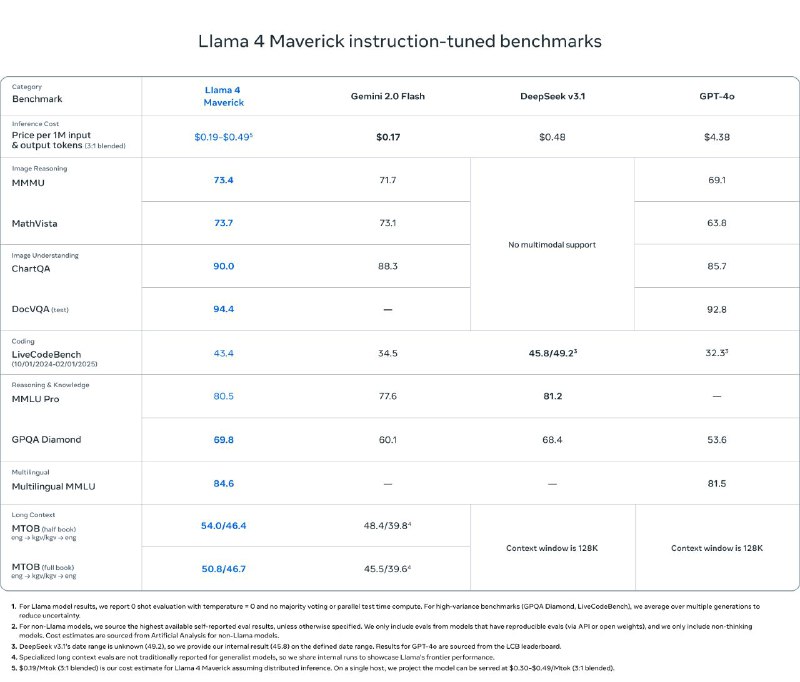
مدل Maverick هم که از همون تعداد پارامتر فعال اما با ۱۲۸ متخصص بهره میبره، در تستهای گسترده از GPT-4o و Gemini 2.0 پیشی گرفته و با مدلهایی مثل DeepSeek v3 در زمینههای استدلال و کدنویسی رقابت میکنه؛ اون هم با نصف تعداد پارامتر فعال.
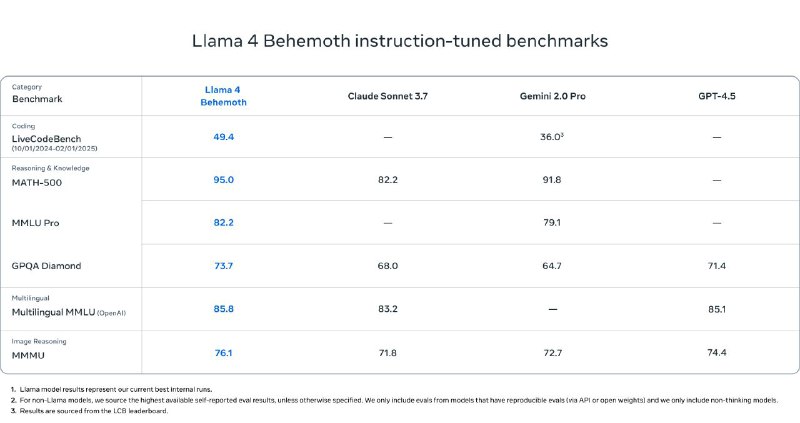
قدرت این مدلها تا حد زیادی مدیون مدل Behemoth هست؛ یک مدل بزرگ ۲ تریلیونی با ۲۸۸ میلیارد پارامتر فعال که نقش "معلم" رو در فرایند آموزش ایفا کرده. Behemoth در بنچمارکهای ریاضی، کدنویسی و زبانهای مختلف عملکردی بهتر از مدلهای شاخصی مثل GPT-4.5، Claude 3.7 و Gemini 2.0 Pro داشته. هرچند هنوز بهطور کامل عرضه نشده، اما متا وعده داده بهزودی اطلاعات بیشتری دربارهی اون منتشر کنه.
در طراحی این مدلها، معماری Mixture of Experts بهکار گرفته شده که با فعالسازی بخشی از پارامترها بهازای هر توکن، هم بازدهی محاسباتی رو افزایش داده و هم کیفیت مدل رو نسبت به مدلهای متراکم بهبود داده. Llama 4 همچنین بهصورت چندوجهی طراحی شده و میتونه همزمان ورودیهای متنی و تصویری رو پردازش کنه. در فاز آموزش، از دادههای متنی، تصویری و ویدیویی در مقیاس بالا استفاده شده و تکنیکهای جدیدی مثل MetaP برای بهینهسازی هایپرپارامترها بهکار رفته.
در مرحله پسآموزش، متا از روشهای جدیدی مثل یادگیری تقویتی آنلاین و بهینهسازی مستقیم ترجیحی برای بهبود مهارتهای مدل در استدلال، مکالمه و چندوجهیبودن استفاده کرده.
مدل Maverick با بهرهگیری از این روشها، عملکرد چشمگیری در درک تصویر، تولید متن، پاسخ به پرسشهای بصری و وظایف پیچیده نشون داده. مدل Scout هم با وجود حجم کمتر، در زمینههایی مثل کدنویسی، پردازش کانتکست بلند، و درک تصویری، نتایجی بهتر از تمام نسلهای قبلی Llama ارائه میده.
در نهایت، متا تأکید کرده که این مدلها با بالاترین استانداردهای ایمنی توسعه داده شدن. ابزارهایی مثل Llama Guard، Prompt Guard و سامانهی تست GOAT برای جلوگیری از خروجیهای نامناسب یا سؤاستفاده از مدلها ارائه شده و توسعهدهندگان میتونن این ابزارها رو متناسب با نیاز خودشون تنظیم کنن. همچنین تلاشهایی هم برای کاهش سوگیریهای سیاسی و اجتماعی در پاسخهای مدل صورت گرفته تا Llama 4 بتونه دیدگاههای مختلف رو بهدرستی درک و بیان کنه.
@aipulse24
در این مجموعه سه مدل معرفی شده: Llama 4 Scout، Llama 4 Maverick و Llama 4 Behemoth. دو مدل اول به صورت Open Weight عرضه شدن و برای استفاده در پلتفرمهایی مثل WhatsApp، Messenger، Instagram Direct و نسخه وب Meta AI در دسترس قرار گرفتن.
مدل Scout با ۱۷ میلیارد پارامتر فعال و ۱۶ متخصص، قویترین مدل توی کلاس خودش بهشمار میاد و با وجود تواناییهای چشمگیر، روی یک GPU از نوع H100 اجرا میشه. این مدل با داشتن پنجره کانتکست ۱۰ میلیون توکنی، عملکردی بهتر از مدلهایی مثل Gemma 3 و Gemini 2.0 Flash-Lite ارائه میده.
مدل Maverick هم که از همون تعداد پارامتر فعال اما با ۱۲۸ متخصص بهره میبره، در تستهای گسترده از GPT-4o و Gemini 2.0 پیشی گرفته و با مدلهایی مثل DeepSeek v3 در زمینههای استدلال و کدنویسی رقابت میکنه؛ اون هم با نصف تعداد پارامتر فعال.
قدرت این مدلها تا حد زیادی مدیون مدل Behemoth هست؛ یک مدل بزرگ ۲ تریلیونی با ۲۸۸ میلیارد پارامتر فعال که نقش "معلم" رو در فرایند آموزش ایفا کرده. Behemoth در بنچمارکهای ریاضی، کدنویسی و زبانهای مختلف عملکردی بهتر از مدلهای شاخصی مثل GPT-4.5، Claude 3.7 و Gemini 2.0 Pro داشته. هرچند هنوز بهطور کامل عرضه نشده، اما متا وعده داده بهزودی اطلاعات بیشتری دربارهی اون منتشر کنه.
در طراحی این مدلها، معماری Mixture of Experts بهکار گرفته شده که با فعالسازی بخشی از پارامترها بهازای هر توکن، هم بازدهی محاسباتی رو افزایش داده و هم کیفیت مدل رو نسبت به مدلهای متراکم بهبود داده. Llama 4 همچنین بهصورت چندوجهی طراحی شده و میتونه همزمان ورودیهای متنی و تصویری رو پردازش کنه. در فاز آموزش، از دادههای متنی، تصویری و ویدیویی در مقیاس بالا استفاده شده و تکنیکهای جدیدی مثل MetaP برای بهینهسازی هایپرپارامترها بهکار رفته.
در مرحله پسآموزش، متا از روشهای جدیدی مثل یادگیری تقویتی آنلاین و بهینهسازی مستقیم ترجیحی برای بهبود مهارتهای مدل در استدلال، مکالمه و چندوجهیبودن استفاده کرده.
مدل Maverick با بهرهگیری از این روشها، عملکرد چشمگیری در درک تصویر، تولید متن، پاسخ به پرسشهای بصری و وظایف پیچیده نشون داده. مدل Scout هم با وجود حجم کمتر، در زمینههایی مثل کدنویسی، پردازش کانتکست بلند، و درک تصویری، نتایجی بهتر از تمام نسلهای قبلی Llama ارائه میده.
در نهایت، متا تأکید کرده که این مدلها با بالاترین استانداردهای ایمنی توسعه داده شدن. ابزارهایی مثل Llama Guard، Prompt Guard و سامانهی تست GOAT برای جلوگیری از خروجیهای نامناسب یا سؤاستفاده از مدلها ارائه شده و توسعهدهندگان میتونن این ابزارها رو متناسب با نیاز خودشون تنظیم کنن. همچنین تلاشهایی هم برای کاهش سوگیریهای سیاسی و اجتماعی در پاسخهای مدل صورت گرفته تا Llama 4 بتونه دیدگاههای مختلف رو بهدرستی درک و بیان کنه.
@aipulse24
tg-me.com/learning_with_m/149
Create:
Last Update:
Last Update:
شرکت متا نسل چهارم از مدلهای زبانی Llama را معرفی کرده که با تواناییهای چندوجهی و پشتیبانی از کانتکست بسیار بلند، رقیب بسیار جدیای برای مدلهای اوپن سورس محسوب میشن.
در این مجموعه سه مدل معرفی شده: Llama 4 Scout، Llama 4 Maverick و Llama 4 Behemoth. دو مدل اول به صورت Open Weight عرضه شدن و برای استفاده در پلتفرمهایی مثل WhatsApp، Messenger، Instagram Direct و نسخه وب Meta AI در دسترس قرار گرفتن.
مدل Scout با ۱۷ میلیارد پارامتر فعال و ۱۶ متخصص، قویترین مدل توی کلاس خودش بهشمار میاد و با وجود تواناییهای چشمگیر، روی یک GPU از نوع H100 اجرا میشه. این مدل با داشتن پنجره کانتکست ۱۰ میلیون توکنی، عملکردی بهتر از مدلهایی مثل Gemma 3 و Gemini 2.0 Flash-Lite ارائه میده.
مدل Maverick هم که از همون تعداد پارامتر فعال اما با ۱۲۸ متخصص بهره میبره، در تستهای گسترده از GPT-4o و Gemini 2.0 پیشی گرفته و با مدلهایی مثل DeepSeek v3 در زمینههای استدلال و کدنویسی رقابت میکنه؛ اون هم با نصف تعداد پارامتر فعال.
قدرت این مدلها تا حد زیادی مدیون مدل Behemoth هست؛ یک مدل بزرگ ۲ تریلیونی با ۲۸۸ میلیارد پارامتر فعال که نقش "معلم" رو در فرایند آموزش ایفا کرده. Behemoth در بنچمارکهای ریاضی، کدنویسی و زبانهای مختلف عملکردی بهتر از مدلهای شاخصی مثل GPT-4.5، Claude 3.7 و Gemini 2.0 Pro داشته. هرچند هنوز بهطور کامل عرضه نشده، اما متا وعده داده بهزودی اطلاعات بیشتری دربارهی اون منتشر کنه.
در طراحی این مدلها، معماری Mixture of Experts بهکار گرفته شده که با فعالسازی بخشی از پارامترها بهازای هر توکن، هم بازدهی محاسباتی رو افزایش داده و هم کیفیت مدل رو نسبت به مدلهای متراکم بهبود داده. Llama 4 همچنین بهصورت چندوجهی طراحی شده و میتونه همزمان ورودیهای متنی و تصویری رو پردازش کنه. در فاز آموزش، از دادههای متنی، تصویری و ویدیویی در مقیاس بالا استفاده شده و تکنیکهای جدیدی مثل MetaP برای بهینهسازی هایپرپارامترها بهکار رفته.
در مرحله پسآموزش، متا از روشهای جدیدی مثل یادگیری تقویتی آنلاین و بهینهسازی مستقیم ترجیحی برای بهبود مهارتهای مدل در استدلال، مکالمه و چندوجهیبودن استفاده کرده.
مدل Maverick با بهرهگیری از این روشها، عملکرد چشمگیری در درک تصویر، تولید متن، پاسخ به پرسشهای بصری و وظایف پیچیده نشون داده. مدل Scout هم با وجود حجم کمتر، در زمینههایی مثل کدنویسی، پردازش کانتکست بلند، و درک تصویری، نتایجی بهتر از تمام نسلهای قبلی Llama ارائه میده.
در نهایت، متا تأکید کرده که این مدلها با بالاترین استانداردهای ایمنی توسعه داده شدن. ابزارهایی مثل Llama Guard، Prompt Guard و سامانهی تست GOAT برای جلوگیری از خروجیهای نامناسب یا سؤاستفاده از مدلها ارائه شده و توسعهدهندگان میتونن این ابزارها رو متناسب با نیاز خودشون تنظیم کنن. همچنین تلاشهایی هم برای کاهش سوگیریهای سیاسی و اجتماعی در پاسخهای مدل صورت گرفته تا Llama 4 بتونه دیدگاههای مختلف رو بهدرستی درک و بیان کنه.
@aipulse24
در این مجموعه سه مدل معرفی شده: Llama 4 Scout، Llama 4 Maverick و Llama 4 Behemoth. دو مدل اول به صورت Open Weight عرضه شدن و برای استفاده در پلتفرمهایی مثل WhatsApp، Messenger، Instagram Direct و نسخه وب Meta AI در دسترس قرار گرفتن.
مدل Scout با ۱۷ میلیارد پارامتر فعال و ۱۶ متخصص، قویترین مدل توی کلاس خودش بهشمار میاد و با وجود تواناییهای چشمگیر، روی یک GPU از نوع H100 اجرا میشه. این مدل با داشتن پنجره کانتکست ۱۰ میلیون توکنی، عملکردی بهتر از مدلهایی مثل Gemma 3 و Gemini 2.0 Flash-Lite ارائه میده.
مدل Maverick هم که از همون تعداد پارامتر فعال اما با ۱۲۸ متخصص بهره میبره، در تستهای گسترده از GPT-4o و Gemini 2.0 پیشی گرفته و با مدلهایی مثل DeepSeek v3 در زمینههای استدلال و کدنویسی رقابت میکنه؛ اون هم با نصف تعداد پارامتر فعال.
قدرت این مدلها تا حد زیادی مدیون مدل Behemoth هست؛ یک مدل بزرگ ۲ تریلیونی با ۲۸۸ میلیارد پارامتر فعال که نقش "معلم" رو در فرایند آموزش ایفا کرده. Behemoth در بنچمارکهای ریاضی، کدنویسی و زبانهای مختلف عملکردی بهتر از مدلهای شاخصی مثل GPT-4.5، Claude 3.7 و Gemini 2.0 Pro داشته. هرچند هنوز بهطور کامل عرضه نشده، اما متا وعده داده بهزودی اطلاعات بیشتری دربارهی اون منتشر کنه.
در طراحی این مدلها، معماری Mixture of Experts بهکار گرفته شده که با فعالسازی بخشی از پارامترها بهازای هر توکن، هم بازدهی محاسباتی رو افزایش داده و هم کیفیت مدل رو نسبت به مدلهای متراکم بهبود داده. Llama 4 همچنین بهصورت چندوجهی طراحی شده و میتونه همزمان ورودیهای متنی و تصویری رو پردازش کنه. در فاز آموزش، از دادههای متنی، تصویری و ویدیویی در مقیاس بالا استفاده شده و تکنیکهای جدیدی مثل MetaP برای بهینهسازی هایپرپارامترها بهکار رفته.
در مرحله پسآموزش، متا از روشهای جدیدی مثل یادگیری تقویتی آنلاین و بهینهسازی مستقیم ترجیحی برای بهبود مهارتهای مدل در استدلال، مکالمه و چندوجهیبودن استفاده کرده.
مدل Maverick با بهرهگیری از این روشها، عملکرد چشمگیری در درک تصویر، تولید متن، پاسخ به پرسشهای بصری و وظایف پیچیده نشون داده. مدل Scout هم با وجود حجم کمتر، در زمینههایی مثل کدنویسی، پردازش کانتکست بلند، و درک تصویری، نتایجی بهتر از تمام نسلهای قبلی Llama ارائه میده.
در نهایت، متا تأکید کرده که این مدلها با بالاترین استانداردهای ایمنی توسعه داده شدن. ابزارهایی مثل Llama Guard، Prompt Guard و سامانهی تست GOAT برای جلوگیری از خروجیهای نامناسب یا سؤاستفاده از مدلها ارائه شده و توسعهدهندگان میتونن این ابزارها رو متناسب با نیاز خودشون تنظیم کنن. همچنین تلاشهایی هم برای کاهش سوگیریهای سیاسی و اجتماعی در پاسخهای مدل صورت گرفته تا Llama 4 بتونه دیدگاههای مختلف رو بهدرستی درک و بیان کنه.
@aipulse24
BY Learning With M

Share with your friend now:
tg-me.com/learning_with_m/149